
CS336 - Tokenizer
Relevant Materials and Websites
"Let's build the GPT Tokenizer" From Andrej
or could see the translated version on bilibili
https://tiktokenizer.vercel.app/
Intro
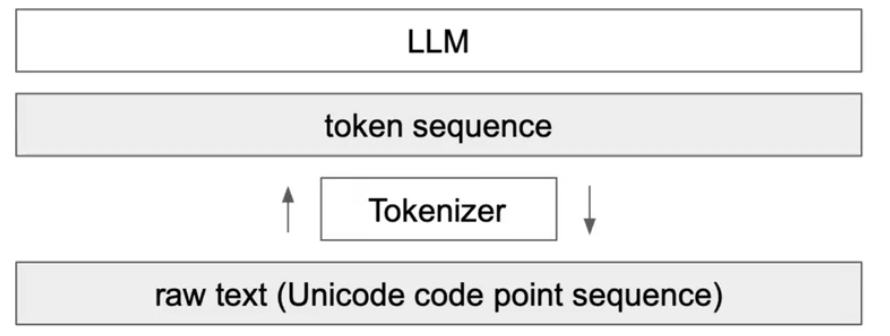
我们为什么需要 Tokenizer
对于大语言模型来说,我们没有办法将原始的 raw text 直接输入神经网络,而是需要将他们变成可以处理的数字进行输入。这就意味着,我们要想办法将 raw text 编码成数字序列。
Character Level
编码成数字序列,最简单的想法就是按照字母来编码 -- character level,但是这样会出现很多的问题:
- 原始文本将会被编码成一个非常长的数字序列,而 Transformer 的注意力是有上下文限制的(Transformer 自注意力的计算复杂度是 ,序列长度翻倍,计算量翻四倍),过长的序列显然会大大影响注意力机制的性能。
- 还有一个问题就是,单个字母携带的语义密度极低,模型需要花费大量的时间去学习把字母组合成词这个基础的事情,而不是直接学习语义关系
- 不同语言下的文本,还有数学公式、代码等混合文本,使用 character level 非常难处理
Word Level
- Out-of-vocabulary:对单个词汇进行编码,但是这就会导致表达性不够。模型遇到训练时没见过的词就只能映射到一个
<UNK>token,完全丧失信息。比如一个新的专有名词 "ChatGPT",word-level tokenizer 如果没见过,就直接变成<UNK>。 - 词汇表爆炸:英语的词形变化(run/runs/running/ran)、德语的复合词、中文的词语组合,如果每个词都是独立 token,词汇表可能需要几十万甚至上百万条目,embedding 矩阵会非常庞大。
- **跨语言不友好:**中文没有天然的空格分词边界,日文混合了汉字、平假名、片假名,word-level对这些语言几乎无法通用
- ...... etc
Tokenizer 的本质目标
在有限的词汇表大小下,最大化序列的压缩率,同时保持对任意输入的完整表达能力。
如何设计 Tokenizer
Tokenizer 就是为了在表达性以及效率(压缩文本)上达到一个平衡。为了这样的平衡,课程中使用的是 BPE 算法,使用 utf-8编码。因为 utf-8 按照 raw bytes 编码 -- 如果要直接 including all the unicode symbols 那么基础的词汇表就要十多万个,而 byte-level version 只需要最基本的 256 个;世界上每一个字符都可以表达(utf-8是对 Unicode 的一种编码方式);且动态编码 1~4 个字节,完全兼容 ascii 编码。
课程中的 Tokenizer 的设计
具体怎么设计 Tokenizer:
- 首先确定 最初始的词汇表,
utf-8对应一个字节所有的可能 256 个,同时加上一些特殊 token。这样组成最原始的词汇表。 - ps:在此之前需要做** Pre-Tokenization **处理,先用正则表达式对文本做预分割。比如 GPT-4 的 tokenizer 会用正则把文本切成:单词、数字序列、标点、空白等不同类别的 chunk,然后 BPE 只在每个 chunk 内部做合并,不跨 chunk 合并。
- 然后针对不同的文本,包括不同语言,代码块等等,进行训练,将他们全部从 raw text
encode成 token sequence,之后就是找出出现频率最高的token pair,将他们 merge 组合成新的token,扩充词汇表。 - Special tokens 的设计:常见的包括
<|endoftext|>、<|im_start|>、<|im_end|>(chat模型的对话边界)、<pad>等。这些 token 不是通过 BPE 训练得到的,而是手动添加进词汇表的,它们承担着控制信号的角色。
除此之外,业界其实还不只有 BPE(Byte Pair Encoding),其余的 Tokenizer 训练的算法有WordPiece(Google BERT 使用),Unigram Language Model(SentencePiece 中的实现)等等
详细讲讲 UTF-8 以及 unicode
https://www.reedbeta.com/blog/programmers-intro-to-unicode/
- 先看看上面的这篇 blog 再好好整理一下这部分
需要进一步思考的点 -- 我们抛开课程中要求实现的算法
基于统计学的 tokenization 的好与坏
BPE 算法在做的是基于频率驱动的字典学习,是在将语料中反复出现的局部模式变成单个的离散符号,从而提高压缩率。
但是基于频率驱动一定就是好的算法实现吗?不一定,它在做的只是统计学上的好,而并非考虑到自然语言上的好。
基于统计学上的 tokenization 是在做模型友好的离散压缩,可能会分词分得不符合自然语言。
我之前说 Tokenization 的本质目标是在有限的词汇表大小下,最大化序列的压缩率,同时保持对任意输入的完整表达能力。
这里的本质目标除去压缩率,完整表达能力,还有“表达能力”,因此分词能达到自然语言的意义上的“分的好”,也许是一个不错的 idea。
对上述一些看法的 “拨乱反正”
在 Andrej Karpathy 的视频 "Let's build the GPT Tokenizer" 中,他在使用 SentencePiece 这个库的时候,有提到,在 LLM 流行之前的 NLP 领域,Normalization 是非常自然且普遍的做法 (像是机器翻译、文本分类等领域)
传统的 NLP 领域依赖的是相对浅层的模型和有限的词表,他们会把大小写统一,会把 "don't" 拆成 "do not",并且去掉标点符号等等。这些 Normalization 实际上是在丢弃信息,目标是在人为手动地去合并变体,缩小输入空间。
为什么 LLM 时代不这么做了呢?
- Text Normalization 是有损的。大小写统一就会丢失区分专有名词的语义,去掉标点会丢失语义信息和语气信息,同时还有语气和风格上的信息的丢失。LLM 已经有足够的模型能力和容量去学习这些关系了,不需要人为去约束,去启发
- 分词器 tokenization 解决了词表爆炸的问题,而不需要人为 Normalization
- 同时 LLM 的本质目标就是为了生成自然、真实的文本,如果训练时使用的都是 normalized 的文本,我们怎么能达到生成自然真实的文本的目标呢?
- 所以说,现在大家都把事儿交给 LLM 自己学,给你足够的数据和算力,你自己去学习。这就是scaling 时代,力大砖飞。
传统 NLP 的 Normalization 是在模型能力不足,算力不足的情况下的一种人工补偿。当模型规模足够大,算力足够的情况下,这种补偿就不再必要了 -- 我们需要尽量减少手工特征工程,这是 LLM 时代给出的回应。LLM 的成功也证明了这一点是有效的。
因此 Tokenizaition 并不是要达到自然语言意义上的 “分的好”,而是要达到模型友好,剩下的就交给模型自己去学。
但是依然要保持一个批判的态度,normalization 这样的做法也是在客观条件受限下的一种解法。解法总是与时俱进的,不断优化当下的解法,并能够革新、提出新的解法是最重要的。
pre-tokenization != text normalization
Question:
再更加深入地了解了一点 tokenization 的实现后,我发现:GPT4、GPT2 的 tokenizer,都是有一个正则表达式来处理文本的,这个和传统 NLP 领域的 Normalization 又有什么不同呢?这是我感到混乱的一点。
传统 NLP 的 normalization 是在丢弃信息:lowercase、去标点、词干化(running → run)。目的是合并变体,缩小输入空间。
GPT-2/GPT-4 tokenizer 里的 regex 做的事情完全不同——它是在切分边界,告诉 BPE 算法"不要跨越这些边界去合并"。regex 不删除任何字符,不改变任何字符,原文的每一个 byte 都被保留了,并没有丢弃信息。
GPT 2 paper 中举了一个例子,原文是这样的
We observed BPE including many versions of common words like dog since they occur in many variations such as dog. dog! dog? . This results in a sub-optimal allocation of limited vocabulary slots and model capacity. To avoid this, we prevent BPE from merging across character categories for any byte sequence. We add an exception for spaces which significantly improves the compression efficiency while adding only minimal fragmentation of words across multiple vocab tokens.
dog. dog? dog! 的例子具体在说什么?
如果我直接在整段文本上跑 BPE,算法只看频率统计。假设训练数据中 "dog." 一起出现了很多次,BPE 可能会把 "dog." 合并成一个 token。同理 "dog!" "dog?" 也可能各自成为独立 token。这就带来了一个大问题 -- 词表里出现了三个本质上都包含 "dog" 的 token,它们各自有独立的 embedding,模型需要额外的工作去学会它们共享 "dog" 这个语义,而且词表空间被浪费了。
所以 GPT-2 的 regex 先把文本切成片段,大致的逻辑是:字母序列是一个 chunk,标点单独是一个 chunk,空白单独是一个 chunk。这样 "dog." 会先被切成 "dog" 和 ".",BPE 只在各自的 chunk 内部做合并,永远不会跨边界把 "dog" 和 "." 粘在一起。
语料偏好
我们首先需要对模型的使用场景进行确认 -- 专注于哪一门语言或者是跨语言,是主要用于生成文本还是专注于代码生成...
我们先考虑这些使用场景,确定训练语料的分布 -- 这也决定了我们的 tokenizer 的偏好。
eg:比如主要是英文场景,输入的训练语料大部分都是英文的话,那么对于中文等其他语言的分词就分得没那么好,同理还会影响代码,空格换行还有缩进的模式。
todo -- 去多了解了解其他的 Tokenizer 设计和策略
to be continued...
Tokenizer 实践 -- 具体在 Assignment 1 中
prerequisites
在进行 Tokenizer 的实际训练之前,我们先要对训练语料做一些提前准备,包括:
- normalization:包括空白处理、全角半角处理、大小写处理等等
- pretokenization:在做 BPE 之前,确定是否需要按照某些规则切开,包括空格、标点符号、代码符号、缩进换行等
- special token 的设计:这里就先不赘述了
更加完整地说,tokenizer 的设计,包含以下的方面:
- 基础的词汇表(符号) -- 课程中使用 unicode 并且使用
utf-8 - 训练语料归一化-- normalization
- pretokenization
- 子词的学习算法(比如 BPE),即按照怎么样的算法来扩充我们的词汇表
- special tokens design
Tokenizer 与整个 LLM 系统
同时 Tokenizer 的 好与坏 不完全由 tokenizer 自己决定,Tokenizer 是整个 LLM 系统设计中的一部分,是需要和模型的大小、上下文的长度、训练token的分布(主要是代码还是通用模型呢)、推理系统吞吐要求等等联动的,而不是一个单一的模块。
因此最后 Tokenizer 的 Best Practice需要找到一个 总系统最优的点。
计算机系统中的 Amdahl 定律,指出只有优化系统中最耗时的部分,才能获得最大的全局性能收益。而在 LLM 系统中,我需要进一步探索怎样才能获得最大的全局性能收益。
vocab 太小,会导致压缩率差,序列长,训练和推理的成本变高;而 vocab 太大又会导致 embedding 矩阵过大,稀疏和低频的 token 过多 -- 有一些 token 训练不足,反而会导致泛化性能下降。
Comments
Powered by GitHub Discussions via Giscus.